I am a product leader and independent AI researcher with more than fifteen years of experience building AI-native enterprise SaaS products. My focus is zero-to-one innovation: translating ambiguous ideas into validated product-market fit. Across multiple initiatives, I have led products from early hypothesis and prototype to eight-figure annual recurring revenue and sustained enterprise adoption in global markets.
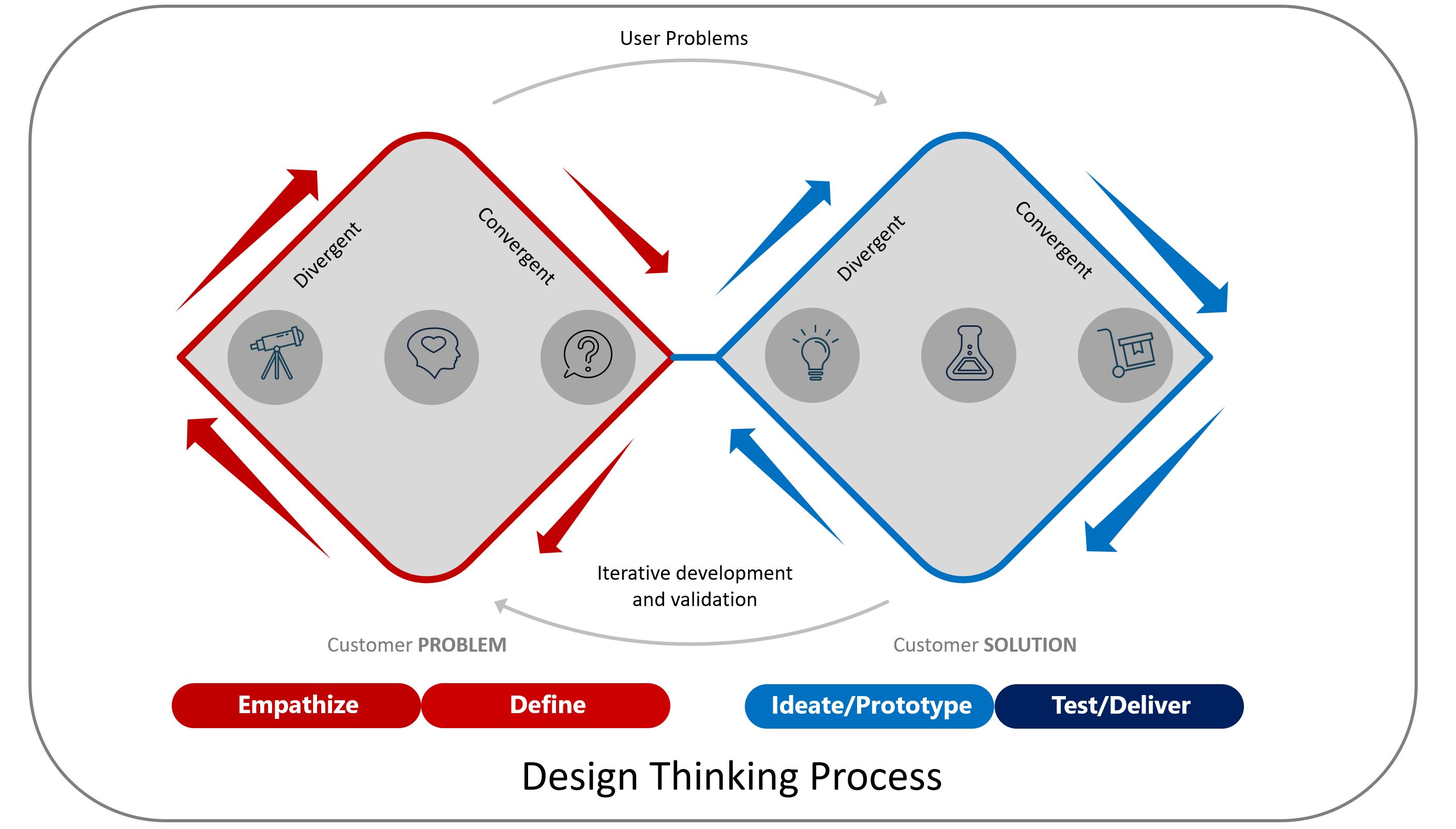
My work begins with disciplined problem framing. Through qualitative research and quantitative validation, I identify customer pain points that are prevalent, consequential, and time-sensitive — the problems worth solving at scale. From this foundation, I define a clear product vision and strategy that directly connect user outcomes to business economics. I approach product strategy as an integrated system: customer insight shapes the value proposition, the value proposition shapes the monetization logic, and the monetization logic shapes roadmap prioritization. The result is a data-informed roadmap in which every initiative is tied to measurable outcomes, not outputs.
I collaborate with marketing and sales across the full go-to-market lifecycle. This includes defining user and buyer personas, articulating differentiated positioning, shaping pricing and packaging strategy, and enabling sales with narratives grounded in economic value. I measure success by demonstrated product-market fit, repeatable revenue, customer adoption, and the establishment of sustainable competitive advantage.
I bring deep expertise in AI systems, machine learning, data platforms, cloud computing, and enterprise SaaS architectures. This foundation enables me to lead the definition and development of autonomous agents, domain-specific AI services, advanced models, and data products engineered for regulated industries. I design AI-native products where intelligence is foundational to the value proposition. Privacy, governance, reliability, and auditability are embedded in the definition, ensuring solutions that are innovative, defensible, and production-ready for enterprise environments.
Alongside industry work, I conduct independent research on responsible AI and risk evaluation. I developed BEATS, a benchmark for assessing bias and structural fairness in large language models, and SHARP, a risk-based framework for quantifying social harm across dimensions including fairness, ethics, and epistemic reliability. These frameworks introduce structured, reproducible methods for evaluating AI systems beyond surface-level performance metrics. My work has been published in the MIT Science Policy Review, arXiv, IEEE, Mind the Product, and other reputable industry publications.
I operate as a strategy-to-product builder, translating customer insight into product vision, aligning economics with architecture, and shipping AI systems that generate measurable business outcomes.