Building Nom Navigator AI: Enhancing Search and Product Recommendation with Generative AI
Introduction
Have you ever found searching for the perfect restaurant to be a tedious task? With standard search methods, it’s often challenging to locate that hidden culinary gem or a dining spot that precisely matches your unique preferences. The overwhelming number of user reviews available online can make this process even more daunting, leaving you indecisive even after extensive reading.
Enter Nom Navigator AI, your personal dining concierge. This Gen AI-powered restaurant recommendation app is like having a knowledgeable foodie friend who understands exactly what you’re seeking in a dining experience. It offers custom-tailored recommendations, making the search for your ideal restaurant effortless and enjoyable.
You can try the prototype here: https://aloknomnavigatorai.streamlit.app/
Why Choose Nom Navigator AI?
- User-Friendly Natural Language Search: Interact with NomNavigatorAI just like you would with a friend. Simply express your cravings and requirements in plain language, and let the app do the rest.
- Discover Hidden Culinary Treasures: Nom Navigator AI excels in uncovering lesser-known dining spots that align perfectly with your search criteria.
- Efficient Review Summarization: Forget the hassle of sifting through hundreds of user reviews. Nom Navigator AI presents you with concise, summarized user review to aid your decision-making process.
Example of How It Works:
Imagine you’re in search of a restaurant near a waterbody, offering a serene ambiance and delightful cuisine. With Nom Navigator AI, you can perform a search using natural language, just as you would ask a friend. The search result comes up with a list of restaurants that meet your specific needs. The app also provides summarized user reviews and a handy link to Google Maps, ensuring you can easily navigate to your chosen culinary adventure.
Say goodbye to imperfect searches and hello to dining perfection with Nom Navigator AI. Let’s search for “I am looking for a restaurant with view of a lake, good ambience and good food.”
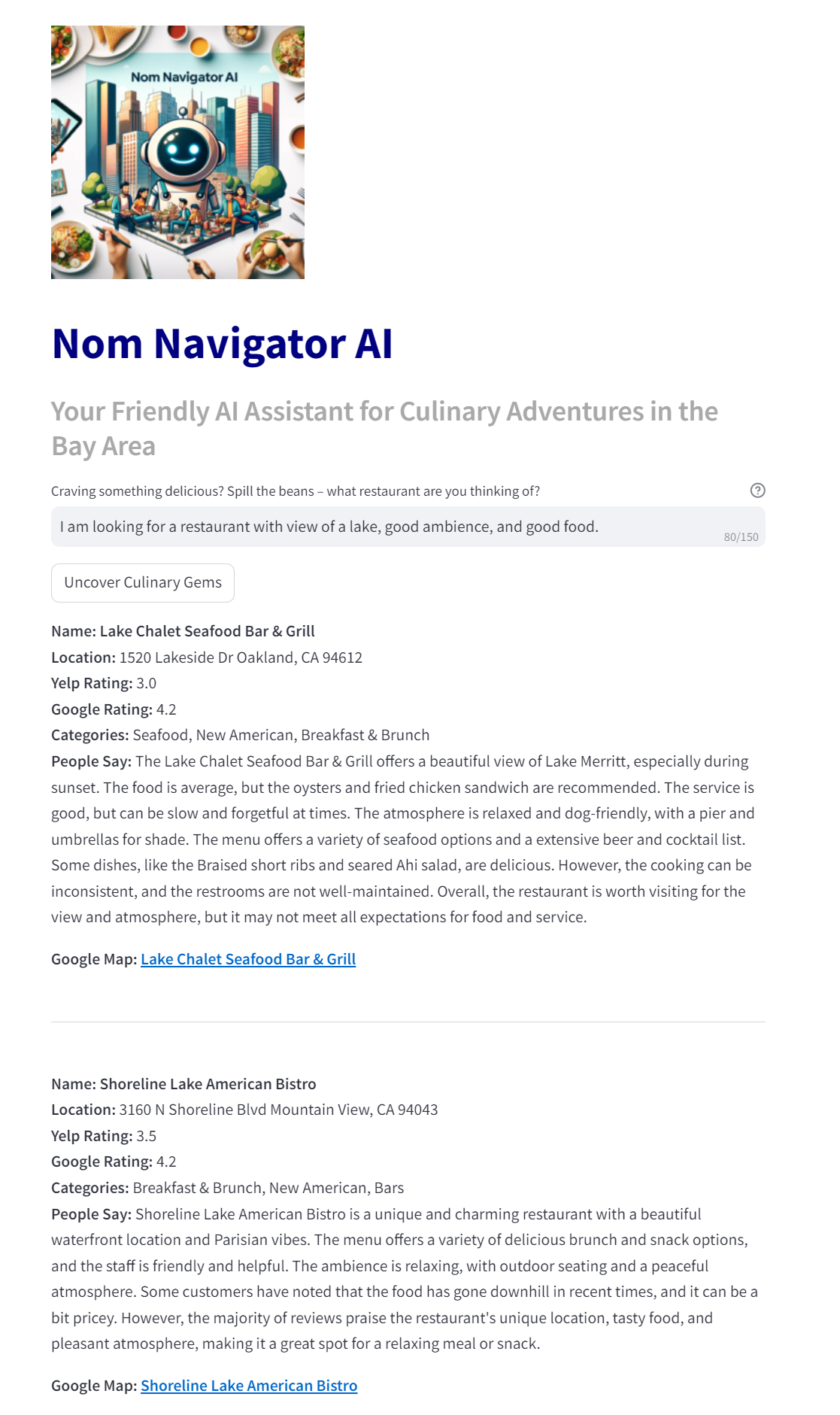
Why is it a game changer?
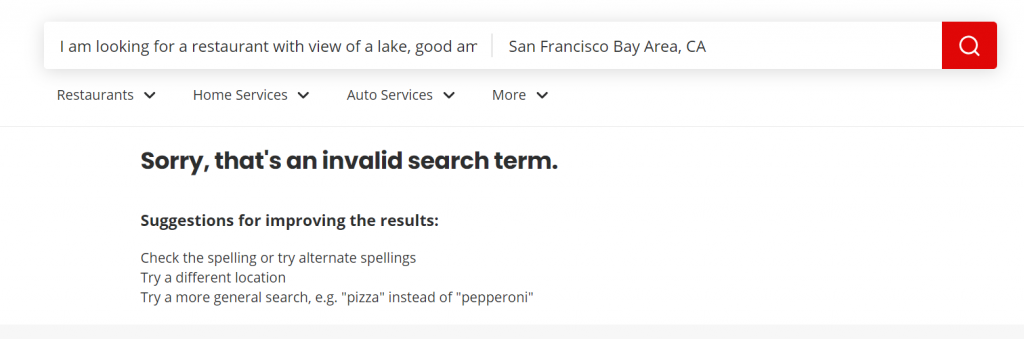
To demonstrate the value let’s just search the same natural language query in popular search platforms.
Search #1: Invalid search term, really?
Search #2: Okay, so why do I need to read so many articles on restaurants with views?
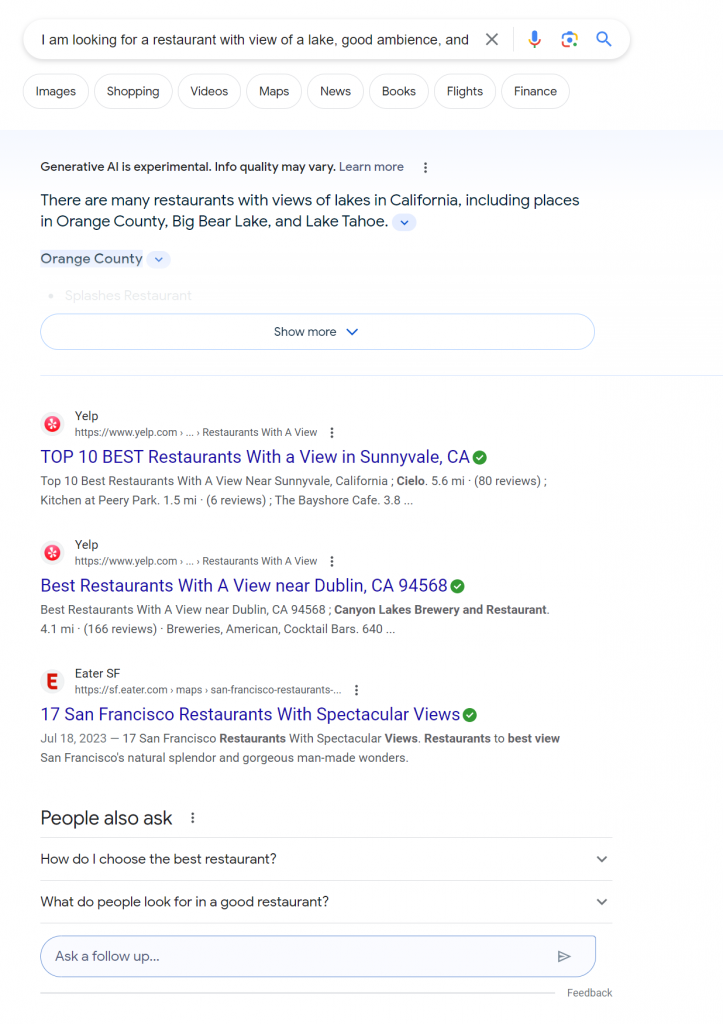
As you can see the traditional search results are not built for nuanced search with semantic meaning. These traditional search engines work well for keyword based search but not for natural language based nuanced search which is an important and prevalent user need.
Why Generative AI in search and recommendation
“There’s nothing that cannot be found through some search engine or on the Internet somewhere.” – Eric Schmidt
“The ultimate search engine would basically understand everything in the world, and it would always give you the right thing. And we’re a long, long ways from that.” – Larry Page
In the context of search and information retrieval systems, the contrasting perspectives from Eric Schmidt and Larry Page offer a unique insight into the current state and the potential future of search engines. I think Generative AI plays a crucial role in bridging the gap between these two perspectives. Generative AI has the potential to transform search engines from mere tools for information retrieval into intelligent systems that comprehend, interpret, and provide precisely what users seek. Advancement in Gen AI will help us move closer to the ideal of an ultimate search engine.
Generative AI introduces a nuanced, context-aware approach to search and retrieval that contrasts sharply with traditional search methods. Traditional algorithms, like PageRank and Boolean search, operate on a deterministic basis, heavily reliant on keywords and direct matches. In contrast, Generative AI, based on transformer architectures, uses advanced encoding and decoding mechanisms to interpret and respond to queries. These models encode input data, such as search queries, into a multi-dimensional vector space. This process captures not just the literal words but the context, nuances, and relationships within the sentence, considering each element in relation to others. The decoding mechanism then generates contextually appropriate responses, moving beyond mere keyword matching.
Once a query is encoded into vector form, Generative AI based retrieval system performs a similarity search (for example: cosine similarity or euclidean distance), seeking vectors (representing documents, web pages, etc.) that closely match the query vector in semantic terms, not just word-to-word, but in overall intent and nuanced meaning. This method improves on algorithms which focus on word frequency and rarity such as Term Frequency-Inverse Document Frequency (TF-IDF), which calculates a word’s relevance in a document based on its frequency and uniqueness.
Encoding transforms words, phrases, and sentences into vectors in a multi-dimensional space, where the proximity and direction of these vectors represent semantic relationships and meanings. For instance, synonyms might be represented by vectors pointing in similar directions, indicating related meanings. This capability enables Generative AI to grasp the semantic meaning and relationships between words far more effectively than traditional keyword-based approaches, resulting in a search and information retrieval system better suited for natural language based query.
Generative AI models are like having a conversation with a friend who not only hears your words but understands their meaning. Therefore Gen AI offers a more intuitive, conversational interaction with information, aligning more closely with the complexities of human inquiry and language. This marks a significant step forward from the limitations of traditional keyword-based search engines.
Inspiration and Background
Online product research has become an integral part of our shopping routine. I approach online reviews with a healthy dose of skepticism. When researching a product, I not only consult reviews from well-known industry experts but also examine user feedback on various e-commerce platforms. My concern with professional reviews is their potential for bias—whether through sponsorships or other influences. For e-commerce user reviews, two main issues stand out: the prevalence of fake reviews, often sponsored by companies to promote their products, and the tendency for reviews to represent extreme experiences. It seems natural that those who’ve had exceptionally good or bad experiences are more likely to write reviews, as opposed to those with average, uneventful experiences.
AI and Generative AI offer promising solutions to these challenges. Leveraging supervised or unsupervised learning, AI can effectively distinguish between genuine and fake reviews, a task akin to separating chalk from cheese. Generative AI and Large Language Models can alleviate the tedium of sifting through numerous reviews by condensing them into concise, informative summaries that capture the key themes and points, making the review process more efficient and reliable.
This becomes even more relevant considering the limitations of current search engines, where SEO-driven, ad-heavy results often disappoint. For more nuanced and semantically rich searches, traditional keyword-based search engines underperform, as highlighted in an earlier part of this blog.
Over the last year I have been exploring Generative AI by applying my learning in different projects like building a bot that answers questions based on information in PDF files to building a bot that uses Langchain agent framework and performs different tasks. As the next step, I was looking at applying my learning in Generative AI to build something more meaningful. These issues with online reviews, and shortcoming of search engines inspired me to build ‘Nom Navigator AI’, a tool specifically designed to help navigate nuanced culinary search, addressing prevalent problems in the domain of online search and user review.
How it works: system design, architecture, and workflow
High level architecture of Nom Navigator AI is as shown below:
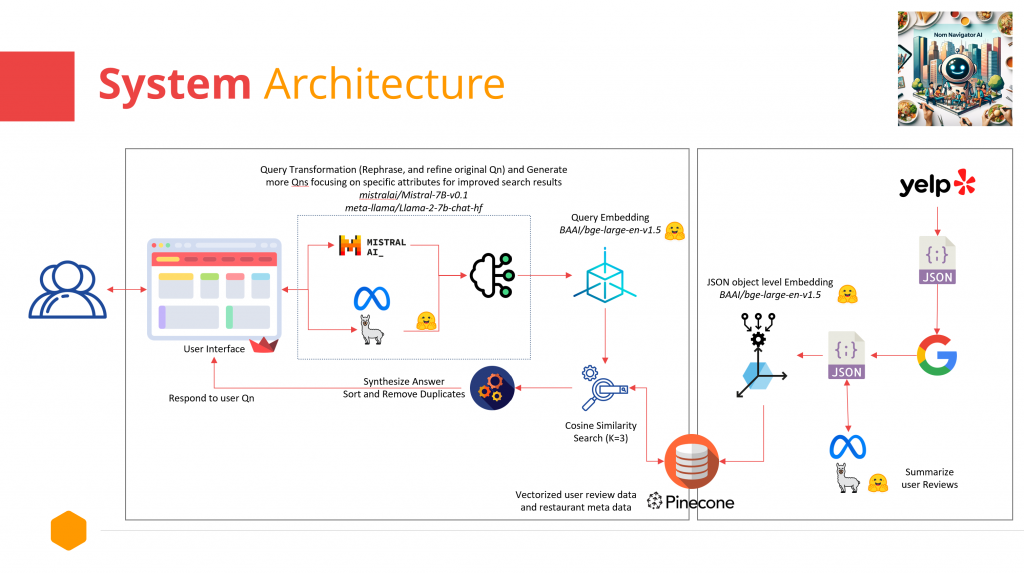
Now let’s dive deeper into the architecture and how it works:
Step #1 preparing the data:
Let’s get the data
I used Yelp Fusion API to get data for restaurants in the San Francisco Bay Area. I then used Google Map’s Find Places API to augment the restaurant data initially fetched from Yelp with data from Google Map. After this step I have a JSON file with restaurant name, restaurant location, Yelp and Google Map rating, user reviews from Google Map and Yelp, and Google Map URL. Now I just need to embed this data at JSON object level (at restaurant level) and store it in a vector database.
Select the embedding model
The choice of an embedding algorithm significantly impacts the effectiveness of retrieval-augmented generation systems. It’s a balance between data privacy needs, semantic richness, language support, computational efficiency, and cost.
I chose BAAI/bge-large-en-v1.5 for embedding because of following reasons:
- I wanted to use an open source model so that I don’t have to call a third party API to get the embeddings. This was not so important for this project in particular and I have used the text-embedding-ada-002 model from Open AI many times in the past. But this time I wanted to use something more representative of the real world scenario where data privacy and security of intellectual property is crucial.
- Support for the English language and performance. BAAI/bge-large-en-v1.5 has consistently performed well in different performance tests. It has been one of the leaders on the Hugging Face’s Massive Text Embedding Benchmark (MTEB) Leaderboard.
- Size and performance: With only 1.34 GB in size BAAI/bge-large-en-v1.5 is pretty easy to run on a laptop. The 1024 dimension dense vector that this model creates performs a fast enough similarity search for my needs.
Selection of vector database
Selecting the right vector database for retrieval-augmented generation (RAG) is crucial for ensuring efficient and accurate information retrieval, which directly impacts the performance of the RAG based application.
When selecting a vector database, it’s important to prioritize high-speed search performance, scalability, and storage efficiency. It’s also important to look for ease of use, and total cost of ownership. Robust data security and strong API and SDK support are crucial for application development. Vector databases should support integration with various AI models, including popular embedding generators like BERT, GPT, and Word2Vec.
For this project I explored FAISS, Chroma DB, Weaviate, Qdrant, and Pinecone. My experience with FAISS and Chroma DB is very good but I simply chose Pinecone for this project because I find it easy to work with. I plan to work with Weaviate and Qdrant for future project to explore them in more detail.
Creating embedding
Once you have collected the data, decided on embedding mode, and selected the vector database creating embedding is fairly straight forward. The following code shows how I created embedding of user reviews and meta data of restaurants in Pinecone using BAAI/bge-large-en-v1.5.
import os
import dotenv
import json
import pinecone
from sentence_transformers import SentenceTransformer
dotenv.load_dotenv()
# Load Pinecone variables and initialize
Pinecone_API_Key = os.environ.get("PINECONE_API_KEY")
Pinecone_index = os.environ.get("PINECONE_INDEX")
Pinecone_Environment = os.environ.get("PINECONE_Environment")
pinecone.init(api_key=Pinecone_API_Key, environment=Pinecone_Environment)
pinecone_index_name = pinecone.Index(index_name=Pinecone_index)
# Load the Sentence Transformer model
model = SentenceTransformer('BAAI/bge-large-en-v1.5')
# Define the base path for the files
base_file_path = 'file_path'
# I had multiple files, so looping through all of them, if you have a single file just load that file and no need for loop.
file_names = [f"file_name{i}.json" for i in range(1, 15)]
# Loop through each file
for file_name in file_names:
full_path = os.path.join(base_file_path, file_name)
# Load the JSON file
with open(full_path, 'r') as file:
data = json.load(file)
# Process each entry in the JSON file
for entry in data:
review_data = entry['user_review']
# Create embeddings for the review data
embeddings = model.encode(review_data, convert_to_tensor=False)
# Prepare the data entry for Pinecone and add meta data
data_entry = {
'id': str(entry['unique_key']),
'values': embeddings.tolist(),
'metadata': {
# add code for your meta data here
}
}
# Upsert the data entry to Pinecone
pinecone_index_name.upsert(vectors=[(data_entry['id'], data_entry['values'], data_entry['metadata'])])
# Close the Pinecone index connection after all operations are complete
pinecone_index_name.close()
Step#2 processing user query:
Query transformation using LLMs
This, working with LLM foundation models, is likely the most fun part of this project. When building a Generative AI-based application selecting a foundation large language model is critical. I looked at critical capabilities such as language understanding (Support for English language), generation quality and accuracy (hard to systematically measure and control), model size, computational efficiency, generation speed, data privacy (I want to be able to host the model myself so that I can avoid sending the data to third party), integration capabilities (support for library and APIs) and cost.
I have built many applications using OpenAI and LangChain in the past so for this project I wanted to work with an open source model which I can host myself. I looked at several leadership boards including Stanford HELM and Hugging Face Chatbot Arena Leaderboard and selected meta-llama/Llama-2-7b-chat-hf and mistralai/Mistral-7B-Instruct-v0.1 to test and use in the application.
I think it’s important to consider that Generative AI is a fast moving area right now and new improved models come up every other week. Therefore application should be designed in a way so that you can easily replace one LLM with another without too much effort.
I am using these models to refine, transform, and augment user query. My initial plan was to test out these two models and then decide which one to use however what I found was that often the query generated by these LLMs were complementary to each other and overall search result was better when using both LLMs, so I dropped my initial idea and kept using both the models. This is at the cost of added latency, and resources needed to run two models instead of one but for my project it was fine. This is likely not an architecture to use in latency and cost sensitive real world production applications but it was a fun little experiment for my project.
I pass the user query to LLMs with prompt instruction to refine the user query into one clear, direct, and concise question while maintaining the original intent. I also use the LLM to generate new questions specifically focused on attributes such as quality and speed of service, ambience, and food quality to augment user questions. This was inspired by query transformation and RAG Fusion techniques discussed in this blog by LangChain.
The result is that even if the user query has a typo or is incomplete, LLMs generate multiple questions relevant for that search while maintaining the original intent. This approach results in better search results and restaurant recommendations.
I used huggingface_hub, and transformers (AutoTokenizer, AutoModelForCausalLM, and pipeline) libraries to load and use these foundation models.
Query Embedding
To retrieve recommended restaurants, a search in the vector database is necessary. First, the user query must be embedded using the same model that was used for vectorizing the restaurant data. This ensures that a similarity search can be effectively performed to find the best matches.
I used BAAI/bge-large-en-v1.5 to embed the query refined and augmented by LLMs before performing a similarity search in vector DB.
Here’s code snippet of using Llama-2-7b-chat-hf model for query transformation. This code can easily be adapted for other models like Mistral-7B-v0.1
import dotenv
import os
import json
from huggingface_hub import login
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
from sentence_transformers import SentenceTransformer
dotenv.load_dotenv()
# hugging face
HF_API_KEY = os.environ.get("HUGGING_FACE_API_KEY")
login(token=HF_API_KEY)
# setting up the foundation model
llm_model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
llm_pipeline = pipeline(
"text-generation",
model=llm_model,
tokenizer=tokenizer,
)
# read the prompt instruction file for query transformation
prompt_augmentation_file = "prompt_augmentation_config.json"
with open(prompt_augmentation_file, "r") as file:
prompt_augmentation = json.load(file)
# Prompt Instructions for Query Transformation Prompt Augmentation
base_prompt_augmentation = prompt_augmentation["base_augmentation"]
food_quality_prompt_augmentation = prompt_augmentation["food_quality"]
ambiance_prompt_augmentation = prompt_augmentation["ambiance"]
service_with_speed_prompt_augmentation = prompt_augmentation["service_with_speed"]
def process_user_query(user_query):
# Process the user query with the LLM model
# Craft a prompt that instructs the LLM to fine tune the query
prompt = base_prompt_augmentation + user_query
# this process can be used to implement RAG Fusion using other prompt instructions
# I am only show base case prompt augmentation here
# create the pipeline
# you can change variables like temperatures etc based on your need
processed_query = llm_pipeline(
prompt,
max_new_tokens=512,
temperature=0.5,
top_k=50,
top_p=0.5,
num_return_sequences=1,
)[0]["generated_text"]
# Save the refined question returned by LLM
# every LLM responds in a specific way, this codes parses the output of Llama-2-7b-chat-hf model and stores only the fine tuned question.
reformulated_query = (
processed_query.split(":")[-1].split("?")[0].strip().lstrip('"')
)
return reformulated_query
# Process User Question
user_question = "User Query goes here"
augmented_question = process_user_query(user_question)
Here’s code snippet of using bge-large-en-v1.5 model to embed the query and then performing search in vector database. This code returns 3 results but can easily be modified to return a different number of results by changing the top_k variable.
import dotenv
import os
import pinecone
from sentence_transformers import SentenceTransformer
dotenv.load_dotenv()
# for query embedding - same model as vector encoding of the data
embedding_model = SentenceTransformer("BAAI/bge-large-en-v1.5")
# Load Pinecone variables and initialize
Pinecone_API_Key = os.environ.get("PINECONE_API_KEY")
Pinecone_index = os.environ.get("PINECONE_INDEX")
Pinecone_Environment = os.environ.get("PINECONE_Environment")
pinecone.init(api_key=Pinecone_API_Key, environment=Pinecone_Environment)
pinecone_index_name = pinecone.Index(index_name=Pinecone_index)
def get_full_data_for_ids(ids):
# Ensure ids is a list
print("IDs to fetch:", ids) # Debugging line
if not isinstance(ids, list):
if isinstance(ids, str):
# If ids is a single string, convert it into a list
ids = [ids]
else:
# If ids is neither a list nor a string, handle the error
raise ValueError("ids must be a list or a string")
# Fetch full data entries, including metadata, for given IDs
fetch_results = pinecone_index_name.fetch(ids)
return fetch_results
def get_restaurant_recommendations(augmented_question, top_k=3):
# Generate embedding for the processed query
query_embedding = embedding_model.encode([augmented_question])
# Perform a similarity search in Pinecone
query_results = pinecone_index_name.query(query_embedding.tolist(), top_k=top_k)
# Extract IDs and scores from query results
ids_scores = [(match["id"], match["score"]) for match in query_results["matches"]]
# Fetch full data for these IDs
full_data_results = get_full_data_for_ids([id for id, _ in ids_scores])
# Retrieve and format the recommendations
recommendations = []
if full_data_results and "vectors" in full_data_results:
for id, score in ids_scores:
data = full_data_results["vectors"].get(id)
if data:
restaurant_info = data["metadata"]
recommendations.append(
{
# fetch meta data
"score": score, # Include the similarity score
}
)
else:
print("No data returned from fetch operation")
# Sort recommendations based on score in descending order
recommendations.sort(key=lambda x: x["score"], reverse=True)
return recommendations
# Process User Question
user_question = "user query"
augmented_question = process_user_query(user_question)
# Generate Response
recommendations = get_restaurant_recommendations(augmented_question)
Step#3 generate search result:
Retrieval – Cosine Similarity search and retrieving the metadata
This step is fairly straightforward. I query the pinecone database with index and the query operations. It retrieves the IDs of the three most similar records (top_k = 3) in the index, along with their similarity scores. Using the ID I retrieved the actual value and metadata. These fields include name of the restaurant, location, category of restaurant, restaurant ration, google map url and user reviews.
Refine the result from retrieval
Sort, Remove duplicate
Because I am using multiple LLMs and query transformation the search result often results in duplicate results. At this step I remove the duplicates and sort the results based on similarity scores.
Summarize review
One of the important aspects of Nom Navigator AI is to summarize user reviews while maintaining the original intent of these reviews and present it in a concise, and succinct way to help end users in the decision-making process.
At this point I make a call to meta-llama/Llama-2-7b-chat-hf foundation model with prompt instruction to summarize reviews for readability and succinctness while highlighting user likes or dislikes and store the response of LLM in a variable to finally show the user.
Step#4 show result back to the user
Streamlit UI
For the prototype I used Streamlit for its flexibility and ease of use. If I were to put this in production I would explore Flask/Django/JavaScript for this prototype streamlit works good enough.
In the front end UI I capture the user search string and then pass it on to the backend processing engine to transform the query using foundation LLMs and retrieve restaurant recommendations from the vector database.
Once the backend processing returns the response, I display the result using streamlit markdown.
Few more example of the app
Let’s start with something simple: I will search using keyword Chicken Tikka Masala and see how the search performs.
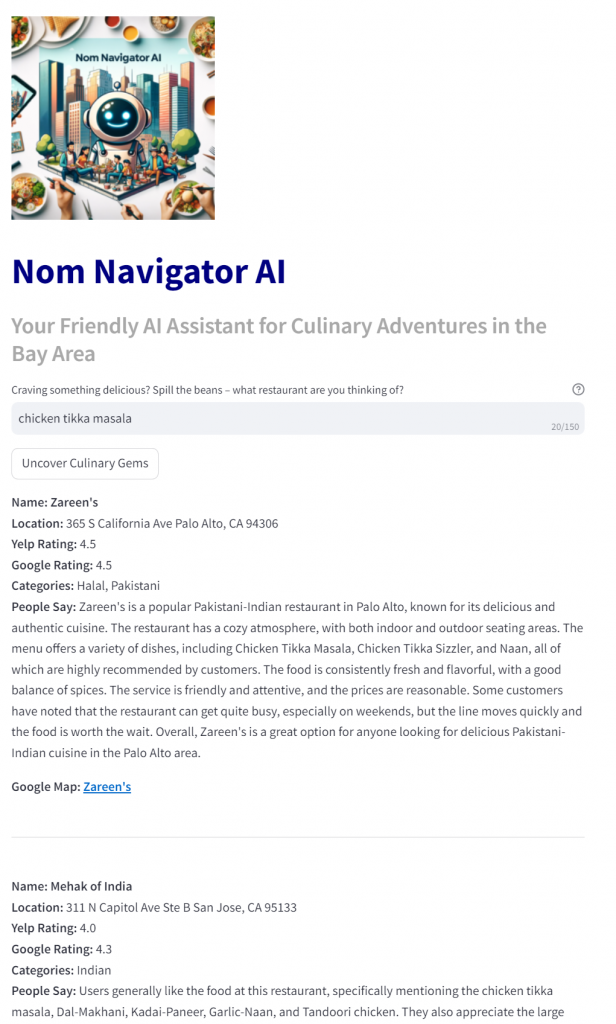
Zareen’s is a popular spot in south bay and has delicious Chicken Tikka Masala. So I can say that the result was fine but this can be achieved using other search engines as well so now let’s take the search up a notch.
Let’s search for “I’m looking for an asian fusion place with best sushi roll” this search has more semantic meaning.
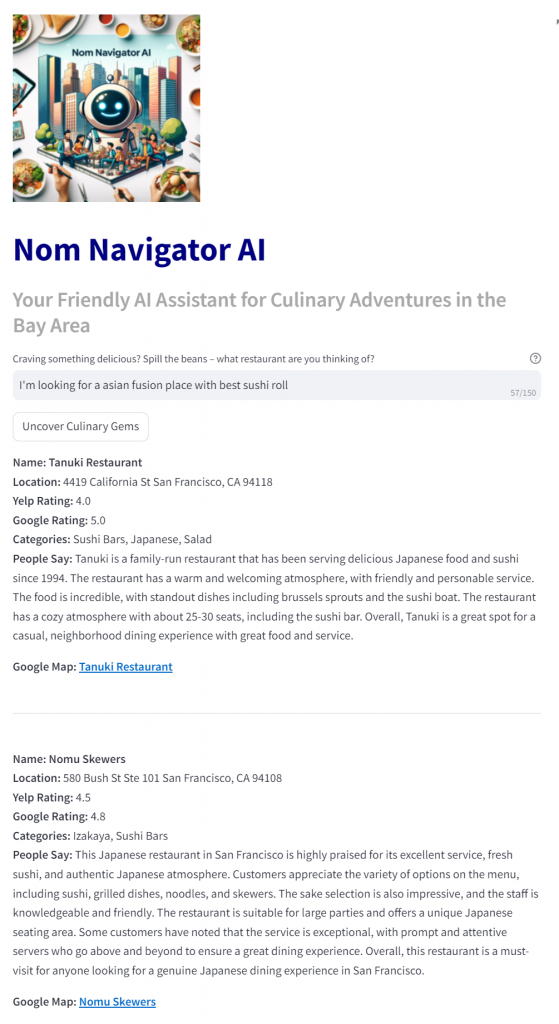
I haven’t been to these restaurants but the result seems to align with the search.
Now let’s make searching even more complicated. Let’s say you are planning for a night out with your significant other and want to plan a memorable dinner. Generally this will involve days worth of search and reading up articles written by food experts and restaurant reviewers. However with Nom Navigator AI you can just search for “I am looking for a restaurant with romantic atmosphere, a beautiful view of the san jose city, and great food for a romantic date night” and voila the result is there:

Here’s the google map link to The Grandview Restaurant and as you can see it has an amazing view of the city.
Future Plans and Updates
What started as an exploratory fun project for the purpose of learning Generative AI transpired into something more meaningful than I had initially planned for. I strongly believe that some of these frameworks can be applied in the real world to improve how users search for and retrieve information (not only a list of restaurants). With that in mind following are some areas I will be exploring next to improve the current prototype even further.
- Adding memory for conservation so that users can ask follow up questions.
- Incorporate Geographic location so that users can search for restaurants in a specific region.
- Improve the search result even further:
- Do a semantic analysis of user questions and extract different contextually important information such as location, emotions, specific needs and then improve the retrieval using these attributes.
- Incorporate few shot prompt
- Improve the sorting beyond just the similarity score.
- Have a multi agent framework where the app can even book a table at a restaurant using publicly available APIs from services like OpenTable or Yelp.
- Explore quality evaluation of query transformation and restaurant recommendation. Peter Drucker said “You can’t improve what you don’t measure.” Evaluation is an increasingly important area for applications built on LLM.
- Security improvement for things like adversarial prompt injection and jailbreaking etc.
Closing Thoughts
Please try the prototype and let me know your thoughts: https://aloknomnavigatorai.streamlit.app/
Generative AI is an incredibly powerful tool that can really enhance your product. They can be used to enhance the user experience, increase the value of the offering, and reduce development time and costs. Generative AI technologies present a fantastic opportunity to boost products’ value, elevate customer satisfaction, generate new revenue streams, and maintain a competitive edge. I hope the insights on Generative AI and Foundation Language Models (LLMs) shared in this blog will inspire and assist you in developing new applications or refining existing ones. If you have any feedback, thoughts, or ideas you’re exploring, please feel free to reach out. I am very passionate about this area and I will be more than happy to help in anyway I can.
Alok Abhishek
I am a seasoned Product Management professional with blended expertise in software engineering and business administration. My passion lies in building innovative products, exploring new technologies, and deepening my understanding of design, business, and data analytics. I'm committed to applying design thinking and data-driven strategies to create products that resonate with customers, particularly within the realms of cloud computing and machine learning. Outside of work, I enjoy expanding my knowledge in science, technology, and business, as well as hiking, running, and attending concerts.


You May Also Like
